这个项目是进入新公司的第一个项目,需求比较简单,后续做起来越发麻烦,中间涉及到并发的一系列的问题,难倒是不难,但是很有参考价值,让我对并发的理解加深了很多!
需求:向Bloomberg发起请求,获取各个国家股票市场的实时交易数据,然后每分钟将当前时刻的数据记录下来,生成CSV文件备份。
刚拿到项目,我理了一下逻辑,业务的主要需求就是两块,一个是将最新的数据实时更新,一个是定时的将数据记录下来,最简单的实现方式就是两个线程处理,一个线程用来实时更新数据,一个线程定时去生成记录文件,第一版代码应运而生。
第一版代码的设计思路:全部业务分为两个线程去处理,也没太多面相对象的思想在里面。主线程负责部分包括:连接Bloomberg,请求数据,解析数据,更新数据;生成文件使用定时任务,每隔一分钟执行一次。
接上Bloomberg后,数据会不断的传过来,对传来的原始数据(Bloomberg设定的element类型)进行解析过后,将股票的id作为主键,存储到hashmap中,根据id对hashmap进行更新;定时任务每隔一分钟,对hashmap进行一个深拷贝,得到一个tem,然后对这个tem进行生成CVS文件处理。大致流程如图所示:
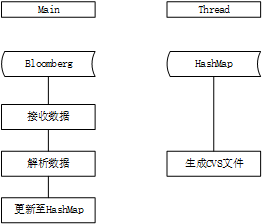
这种实现方式是比较粗暴的,基本没有什么面相对象的思想,按部就班的把流程实现,第一版只是想着把数据跑通,看看会出现什么问题,后续再去优化。在接入欧洲市场后,大概1500支股票的实时交易,在当前代码中是没有问题,紧跟着接入日本市场2000支股票时,开始出现延时和部分数据丢失的情况,在开盘和休盘时间很明显,因为在那个时间点数据的量比较大,一分钟大概有7W笔交易,优化势在必行。
对第一版优化的主要有两点,一是将现有代码进行重构,按照面向对象的方式去实现,增加代码的可读性;二是针对数据量大时出现数据丢失的问题,通过多线程来处理数据。
main线程里只保留部分核心代码,将对数据的处理业务的实现封装到数据处理的对象中,这样main方法中代码量少了很多,主要是连接Bloomberg的方法,生成文件的定时任务的启动,解析数据任务的启动。
考虑到数据丢失的情况,对该问题进行定位,发现是在由于数据量太大,单线程处理不过来,导致数据阻塞甚至丢失,解决的思路就是解析和更新数据过程使用多线程,结合业务的具体场景,决定使用类hash的方式进行处理,根据线程个数对指定市场的所有股票进行均分,每个线程只处理给定的股票集合,通过这种方式可以极大的提升数据处理速率。大致流程图如下图所示:
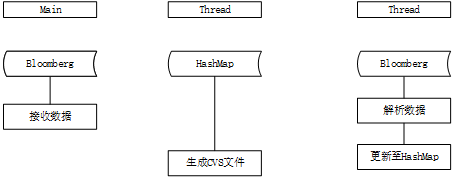
其间还做了一些别的小优化,将解析和更新的步骤合并为一步,解析出来的数据直接存到hashmap中,之前分成两步是考虑代码的可读性,让代码逻辑更清晰;重写了官方提供的解析element的方法,因为通过阅读源代码发现官方代码自己有对解析步骤加锁,会影响速率,索性自己重写了该方法。
整个过程耗时还是有点长的,大概有2个月,没有提供什么文档,获取数据的方式都需要自己去尝试,还有期间测试生成的大量文件,需要写自己脚本,对欧洲、日本和美国三个市场进行实时测试,又是要熬夜去搞,整体下来,收获还是很多的,加深了面相对象思想的理解,同时对多线程处理业务的理解也深刻了。